
Increasing amounts of data driving growth in Artificial Intelligence
The emergence of Artificial Intelligence across industries and sectors has been progressing at a rapid pace and is set to continue in 2019. Forbes predicts that, beyond marketing and sales, multiple new uses for machine learning across industries will emerge in the next year. This rise in AI application is driven by data availability and an increase in connected devices that produce usage and interaction data. According to Gartner, 14.2 billion connected things will be in use in 2019, and that total will reach 25 billion by 2021, producing immense volumes of data.
But producing and analysing this vast amount of data comes at a cost: products or devices need to have a wide array of sensors installed to collect and publish events, which may not be economically viable for all of them. And even when products are completely ‘wired up’ – there is a risk of sensor malfunction, which would mean the collected data contains gaps or faulty values. Finally, some product components contain closed subsystems in which sensor placement is physically impossible.
There are also use cases, such as autonomous vehicle operation, that need enormous amounts of data across many scenarios to be produced and analysed. For example, Toyota has calculated that it takes 14.4 billion kilometres of testing for a vehicle to reach level 5 autonomy, which cannot be achieved by physical testing alone. This means that, although more and more products and devices are connected, data being produced within the IIoT might not have the quality and coverage needed to reliably train an AI algorithm. So how do we solve this issue? Well, say hello to AI’s new partner and match made in data heaven: the Digital Twin.
What is a Digital Twin?
A Digital Twin is a virtual representation of a physical product and has four characteristics. First of all, it contains data, in the form of product definitions, 3D models and physics-based mechanics needed to create an accurate Digital Twin. The more comprehensive the definitions that are taken into account when creating the Digital Twin, the more realistic it will simulate and predict the behaviour of its real-life counterpart. Data, in the form of user or AI-generated input, is also needed as a catalyst to drive the Digital Twin, which in turn generates data that can be used for analysis.
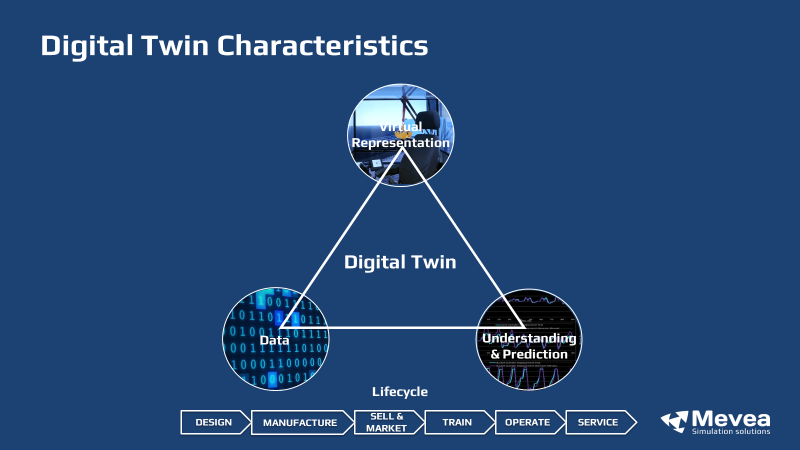
The second characteristic of the Digital Twin is that it contains a virtual representation of the twinned physical asset that allows people to remotely understand its status, its history and interact with it. The third point on the triangle depicted in Figure 1 shows that the Digital Twin can enable understanding and prediction. Ultimately, a Digital Twin is created to understand the behaviour of the physical object under various circumstances and in a variety of environmental conditions, so that its behaviour in the future can be predicted. Finally, the Digital Twin has the ability to produce benefits across the entire product lifecycle: from creating a digital prototype that helps make the design phase more efficient, visualizing solutions in sales and marketing presentations all the way to optimizing machine operation.
3 ways how digital twin can help in AI development
So, how can the Digital Twin help solve the issue of incomplete, noisy or missing data that inhibits the effective training of AI algorithms? In order to be able to do just that, the Digital Twin needs to be an accurate, physics-based representation of a real-life product and its environment. It also needs to be able to resolve a simulation in real-time, so it can produce meaningful and timely data on product behaviour. Once this level of speed and accuracy has been achieved, Digital Twin-generated data can be used to train AI algorithms for a range of different scenarios:
1. Development of assistance or safety systems
For example, to detect pedestrians or objects near an autonomous or remotely operated machine. The Digital Twin could be used to generate training data as well as test solutions that can be used after training in various scenarios.
2. Development of subtask-automation
For example, by using machine learning together with the repeatability of simulation for training neural networks to do specific tasks. An example could be repeating work process scenarios such as excavation, driving or container handling to enable autonomous or assisted machine and vehicle operation.
3. Field data augmentation
For example for small series machines or components, for which not enough training data can be generated or for areas in which sensor placement is physically difficult or economically undesirable. A physics-based Digital Twin of the machine or component can be used to simulate its behaviour with a high degree of accuracy and produce data points that are unobtainable in real-life.
Emerging opportunities
By marrying up Digital Twin technology and AI, exciting new technological developments such as remote or autonomous machine operations and predictive maintenance can be achieved. The Digital Twin can act like a trainer for an AI, tirelessly repeating scenarios and generating data for the AI to learn from. Even though the combination of these two highly complementary technology trends is still at its infancy, the nascent results look promising. Especially when placed in a physics-based Digital Twin approach, AI can be applied to achieve specific learning targets in a focused manner.
Want to learn more about how Digital Twins can help in the development of AI and autonomous machines?

Watch our webinar with AI-expert Ville Hulkko from Silo.AI to learn more about how these two technologies can work together. Read more and watch the webinar recording here!



